
Apache Kafka is all about getting large amounts of data from one place to another, rapidly, and reliably. In computing terms Apache Kafka is a messaging system that is tailored for high throughput use cases, where vast amounts of data need to be moved in a scalable, fault tolerant way. That is why companies like LinkedIn, Netflix, Uber and Airbnb utilize Apache Kafka to provide the messaging infrastructure that can handle hundreds of billions of messages that amount to several hundred terabytes of data being produced, moved around and consumed per day.
Why Apache Kafka?

Figure 1: Sample Enterprise Subsystems
Figure 1 shows a part of how a large enterprise systems looks like. In large companies, there are hundreds of applications all needing data to operate. Now, whether it be creating logs, records in databases, flat files, key value pairs, binary files, or messages, all of these applications are creating data at an incredible rate. Oftentimes that rate can strain existing data stores and require more stores to take on the load. When that happens, you have issues related to getting the data where it needs to be and enabling applications to find it. Furthermore, as businesses change, the variety of the data increases, making the types of applications and data stores change as well. Now, this leads the enterprise systems integrations system to become a complex web of point-to-point data movements that are very hard to manage and work with. Enterprise IT departments have utilized tools and methods to make this complex distribution topology possible. Each of these tools comes with its fair share of trade-offs:
- Database replication and log shipping: This method is limited to a certain kind of data movement between relational databases that support replication, and that’s it. The way a database implements replication is very specific to the database, and therefore doesn’t work across vendors. So in a heterogeneous database environment, this becomes a limitation. As a point to point integration, there is a significant amount of coupling between the source and the target. Changes to the schema have a direct impact on replication. So as your requirements change, the ripple effect can introduce challenges to your replication architecture
- Extract, Transform, and Load (ETL): is used for integrating data between different sources and targets. Every ETL job that runs is a custom application, written by a developer who specializes in ETL. As the data environment increases in complexity, so do the jobs, and as most ETL systems centralize the execution of these jobs, the performance and scalability become strained, as concurrent or sequential jobs compete for the limited resources, which may require multiple ETL environments to exist, which further increases the complexity of the enterprise systems.
-
Message Broker, Messaging makes a lot of sense because it establishes a fairly simple paradigm for moving data between applications and data stores; however, when it comes to a large scale implementation, traditional message systems can struggle. Namely with scalability. The means to collect and distribute data as messages relies on the role of a messaging broker, which is oftentimes a bottleneck. There are a lot of variables that determine the reliability and performance of a messaging system, a big one being message size. Larger messages can put severe strain on message brokers stores, and this a challenge because you may not be able to control messages coming from some systems. Furthermore, a messaging environment is dependent on the ability for message consumers to actually consume at a reasonable rate. There is also the challenge of fault-tolerance. If a consumer pops something off the queue, it’s probably gone. Faults in the consuming applications can happen for any reason, where this becomes a problem is when the bug incorrectly processes the message it is getting from the broker. The broker’s job is to turn over the messages, it doesn’t and can’t keep them around. So if a consumer consumes the message, processes it incorrectly, it can’t go back to retrieve the message again because it’s not there anymore.
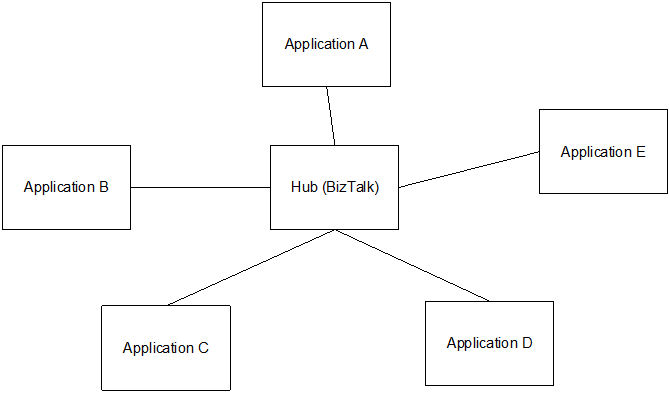
Figure 2: Broker or Hub and Spoke System
Technically, messaging systems are considered a form of Middleware, where you need to write complex logic to handle data movement between applications and data stores. Your code needs to have intimate knowledge of every data store, and that knowledge will likely be specific to the data store type and provider. Furthermore, you will likely be in the realm of dealing with distributed coordinate logic, multiphase commits, and error handling to consistently manage data. This is extremely complex. With every application change, new data store, new schema, you have to revisit this code.
LinkedIn’s Search for a Better Solution
This is the typical enterprise challenge when it comes to handling growing data sets, moving faster and faster through systems. Surely, there has to be a better way to move data cleanly without a complex web of different integration topologies. Reliably, as to reduce the impact of any one component’s slowness or availability on the system. Quickly, as data movement and access is only getting faster for real-time use cases, and finally, autonomously, reducing the coupling between components so we can improve or change parts of the system without a cascading effect. Kafka started as a LinkedIn internal project in 2009. Kafka refers to the German language writer, Franz Kafka, whose work was so freakish and surreal, it inspired an adjective based on his name. For LinkedIn the data infrastructure and the ability to work with it had become so nightmarish and scary that they named their solution after the author whose name would best describe the solution they were hoping to escape from.
Apache Kafka Design Guiding Principles
- Able to handle large volumes of data in the terabytes and beyond.
- Designed to scale out by adding machines to seamlessly share the load.
- Failure tolerant => data had to be reliably managed, transmitted, and made durable in the case of failure.
- Loosely coupled application producers and consumers, but can engage in common data exchanges. It would be unacceptable for one application’s runtime conditions to affect another’s. To enable this loosely coupled paradigm between producers and consumers, they wanted to embody common and simple messaging semantics of publish-subscribe. Independent data producing applications would send data on a topic, and any interested consuming application could subscribe and receive data on that topic, which it could process, and in turn, produce on a different topic for others to consume.
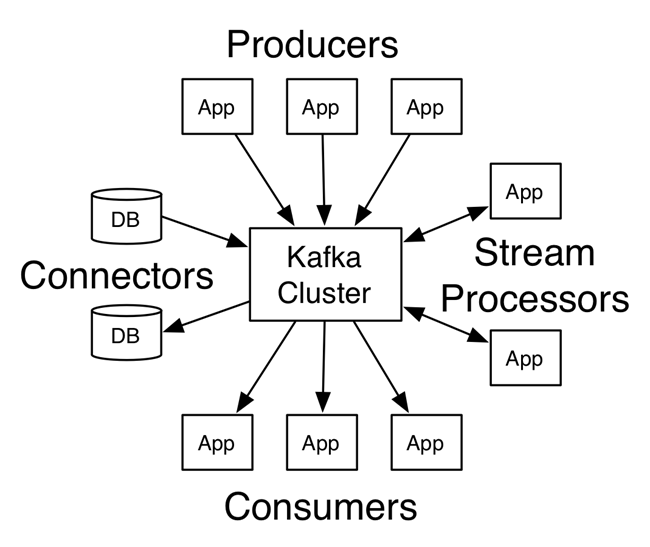
Figure 3: Kafka Cluster
As a central broker of data, Kafka enables disparate applications and data stores to engage with one another in a loosely coupled fashion by conveying data through messaging topics which Kafka manages at scale and reliably. Regardless of the system, the vendor, the language, or runtime, all can integrate into this data fabric, provided by none other than Apache Kafka. Kafka’s development started in 2009, and its first deployment was in 2010. Within the next year, LinkedIn hardened Kafka to a point that they felt it could be released as an open source project under the Apache Software Foundation in 2011. Very soon after its submission to the Apache incubator, it achieved top-level status and has become one of the most adopted tools in the Apache ecosystem. Since 2015, Apache Kafka’s adoption rate has grown 700%, as the software development community contributes more and more capabilities to its code base.
Apache Kafka’s Architecture
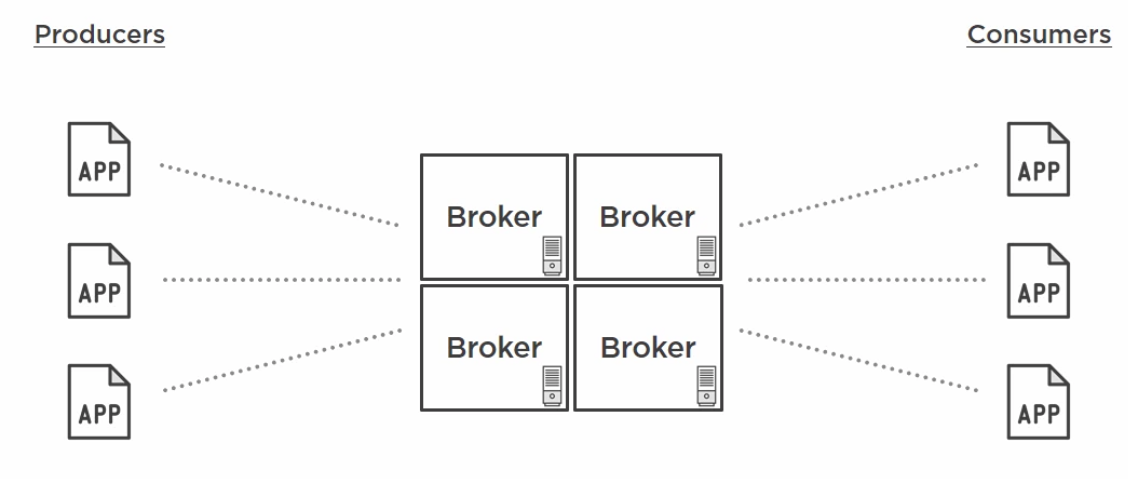
Figure 4: Kafka Brokers
Apache Kafka is a publish / subscribe messaging system. A publisher creates some data and sends it to a specific location where an interested and authorized subscriber can retrieve the message and process it. In Kafka calls publishers= producers, and the subscribers consumers. Producers and consumers are simply applications that you write or use to implement the producing and consuming APIs. Now, the producer sends its messages to w a specific location referred to as a topic, which is really a collection or grouping of messages. Topics have a specific name that can be defined upfront or on-demand, as long as producers know the topic name and have permission to send to it, messages can be sent to that specific location. The same goes for consumers. Consumers retrieve messages based on the topic it is interested in. The messages and their topics are kept in the Broker, as it is in other messaging systems. The Kafka Broker is a software process that runs on a machine. The Broker uses the file system to store messages which it categorizes as topics. Like any executable, you can run more than one on a machine, but each must have unique settings so that they don’t conflict with one another. It is in the Kafka Broker where the differences between other messaging systems become apparent.
The Apache Kafka Cluster
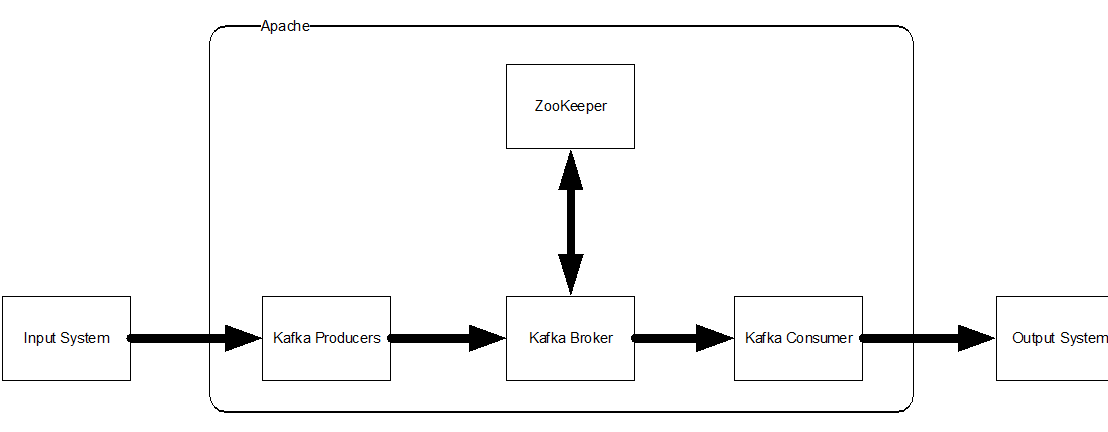
Figure 5: Kafka Cluster components
How the Kafka Broker handles messages in their topics is what gives Kafka its high throughout capabilities. Achieving high throughput is largely a function of how well a system can distribute its load and efficiently process it on multiple nodes in parallel. With Apache Kafka, you can scale out the number of brokers as much as needed to achieve the levels of throughput required, and all of this without affecting existing producer and consuming applications. To achieve h high levels of reliability the Apache Kafka architecture utilizes the Cluster concept. A Kafka Cluster is a grouping of multiple Kafka Brokers. A Kafka cluster is just a grouping of Brokers, it doesn’t matter if they’re running on their own machines or not, what matters is how independent Brokers are grouped to form a cluster. The grouping mechanism that determines a cluster’s membership of Brokers is an important part of Kafka’s architecture, and what really enables its ability to scale to thousands upon thousands of Brokers and be distributed in a fault-tolerant way. For the sake of putting down a placeholder, this is where Apache Zookeeper comes in.
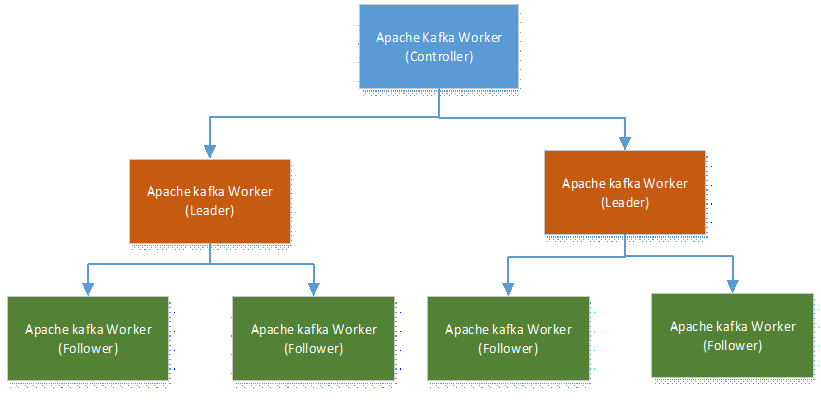
Figure 6: Kafka nodes relationships
A system is a collection of resources that have instructions to achieve a specific goal or function. A distributed system is one that consists of multiple independent resources, also known as workers or nodes; sometimes even called worker nodes. The reason there are multiple nodes is to spread the work around, to get more done. In order to do that, there needs to be coordination amongst all of the available working nodes to ensure consistency and optimal progress towards the overall task or goal at hand. In Kafka, these worker nodes are the Kafka brokers. A controller is just a worker node like any other. The worker node selected as the controller is commonly the one that’s been around the longest. The controller has some critical responsibilities:
- Maintain an inventory of what workers are available to take on work.
- Maintain a list of work items that has been committed to and assigned to workers,
- And maintain active status of the workers and their progress on assigned tasks.
Once a controller is established, and the workers are assigned and available a Kafka cluster. When a task comes in, as an example, from a Kafka producer, the controller has to make a decision which worker should take it. There are a lot of factors at play here:
- The controller needs to know who is available and in good health
- The controller needs to know what risk policy should govern its assignment decisions. An example for a risk policy is the redundancy level, the thing that determines what level of replication to employ in case an assigned worker fails. That means each task given to a worker must also be given to at least one of the worker’s peers in the event of an unexpected catastrophe. For an assignment, if the controller determines redundancy is required, it will promote a worker into a leader, which will take direct ownership of the task assigned. It will be the leader’s job to recruit two of its peers to take part in the replication. Once peers have committed to the leader, a quorum is formed, and these committed peers now take on a new role in relation to a leader, a follower. If for whatever reason a leader cannot get a quorum, the controller will reassign tasks to leaders that can. In Apache Kafka, the work that the cluster of Brokers performs is receiving messages, categorizing them into topics, and reliably persisting them for eventual retrieval.
Distributed Consensus with Apache Zookeeper
Virtually every component within a distributed system has to keep some form of communication going between the nodes. Besides the obvious data payloads being transferred as messages, there are other types of network communications happening that keep the cluster operating normally. For example, events related to Brokers becoming available and requesting cluster membership or Broker name lookups, retrieving bootstrap configuration settings, and being notified of new settings consistently and in a timely fashion, events related to controller and leader election and health status updates, like heartbeat events. That is where Apache Zookeeper comes in. Zookeeper serves as a centralized service for metadata about vast clusters of distributed nodes needing bootstrap and runtime configuration information, health and synchronization status, and cluster and quorum membership, including the roles of elected nodes. Zookeeper itself is a distributed system, and for it to run reliably, has to have multiple nodes which form what is called a Zookeeper ensemble. An ensemble’s like saying a cluster. For Kafka, because of the type of work Zookeeper ensemble performs, it is generally not needed to have more than one ensemble to power one or many Kafka clusters.
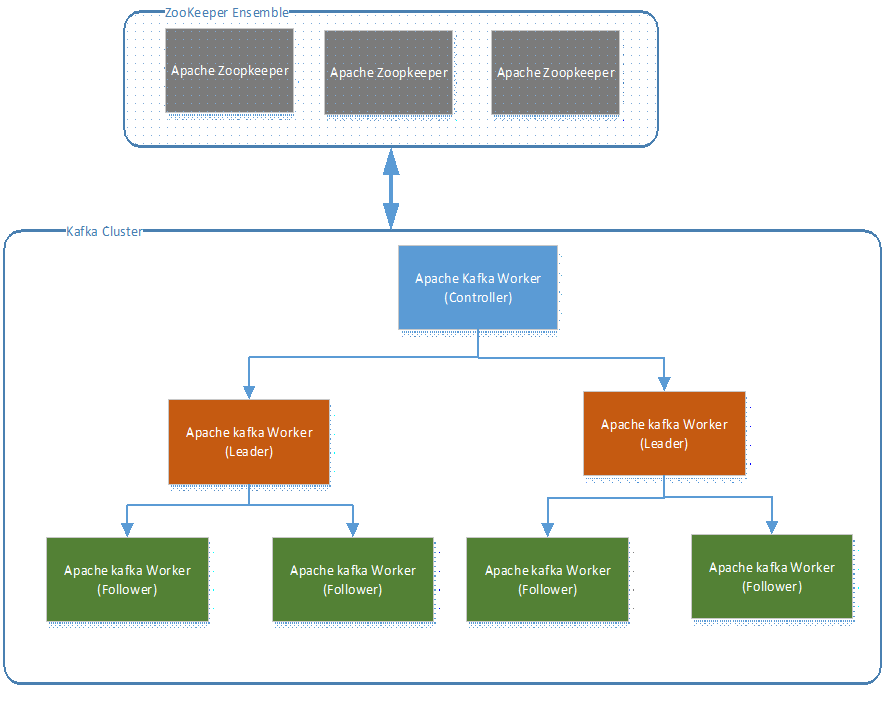
Figure 7: Full Apache Kafka Cluster
At the heart of Apache Kafka, you have cluster, consists of possibly hundreds of independent Brokers. Closely associated with the Kafka cluster, you have a Zookeeper environment, which provides the Brokers within a cluster, the metadata it needs to operate at scale and reliably. As this metadata is constantly changing, connectivity and chatter between the cluster members and Zookeeper is required. Of course, the cluster doesn’t do much unless if you put it to work, and that’s where Kafka producers and consumer applications come in. Each of these components can scale out to take on more demand and increase levels of reliability and availability.
