
In this blog, I will take a vendor agnostic look at cloud computing, both on-premises private cloud computing, as well as public cloud solutions. There is no one size fits all approach to cloud computing, it depends on loads of different business scenarios, what some of the options are and how you go about making the best decision for you and your business. Some of the major topics that we will cover include the differences between public, private, and hybrid cloud computing, what business requirements they each best fulfill, and what some of the architectural caveats are for all of them, the practical differences between the various public cloud service offerings IaaS, PaaS, and SaaS, and what you need know about each of them before making a decision to invest in anything, what are some of the security and management considerations, which are specific to public cloud environments, and how best to manage them or mitigate them completely. And finally, advanced cloud services, such as containerized applications, serverless computing, and machine learning, what they are and why you and your business might wish to take advantage of them.
Defining Cloud Architecture
Like any technical framework, cloud computing comes complete with a wealth of concepts and components. Datacenters have been around for many years, and the concept is a fundamental component of enterprise computing. Mainframe computers, which required specialized rooms to store them in, have been around since the 1960s. For decades, the only functional datacenter model was that of the centralized datacenter in corporate or enterprise head office. With the emergence of client-server computing, it became possible for businesses and home consumers to purchase inexpensive, yet relatively powerful systems, which can serve requests, much in the same way as traditional mainframes. Fewer computing resources were spread across a much larger number of physical machines, hence the de-centralized datacenter. With the rise of internet connectivity, the de-centralized datacenter model meant that businesses could provide a head office experience to remote offices, and eventually to workers in the field, or those working from home. It also became possible for businesses to start bringing that remote, de-centralized infrastructure back to the main datacenter at head office. However, it’s important to realize that the concept of a centralized datacenter is only centralized from the point of view of individual businesses. Zoom out far enough, and you can see that all these centralized datacenters dotted across every city in every country in the world is, from a global perspective, still massively de-centralized.
Virtualization and Commoditization
Virtualization has been around in one form or another for almost as long as mainframes. However, when we think of virtualization, most of us think about the surge in hardware virtualization on commodity server systems, which occurred in the 2000s. Now we’re working with containers. Virtualization has moved beyond providing a virtual hardware environment, and can now provide a virtual operating system kernel. For most of the history of datacenters, the capability of systems to scale has been limited by practical physical constraints, such as the amounts of data you could fit onto the storage media available at the time, the amount of data you could push from one system to the next using whatever networking infrastructure and protocols were available, the amounts of calculations a processor could perform, or the speed at which a system’s internal components could communicate with each other, and many more constraints besides. In the past decade or so, there has been a distinct blurring between what constitutes enterprise-grade and consumer-grade, and this change has been driven by the constant improvement in the quality and capabilities, and the price, a of consumer-grade hardware. Let’s look at an example. To provide robust storage to support datacenter workloads business would traditionally invest in expensive, dedicated storage arrays. Servers which needed to make use of this storage, whether for hosting virtual machines, storing data, or supporting high-performance databases, were presented with preconfigured storage volumes. The servers acted as pure consumers of the storage, which was controlled and presented by the array. Fast forward to today and we’re now at the point where each physical server has the power and capability to act as a fully redundant storage array , simply using commodity disks, working in conjunction with other identical systems in the same datacenter across a high-speed networking back plane, and enterprises can now build their own highly-scalable storage fabric. This ability to reduce the reliance upon specialized hardware solutions and build out one’s own solutions using the native capabilities of commodity physical server hardware has been critical in the evolution of centralized computing within datacenters and the unlocking of global-scale centralized computing, which lies at the heart of cloud computing.
Service-driven Architecture
Consider the case of a manger who has been tasked with implementing a new application, which their company has purchased. In times past, the manager would have gone to the company’s IT department asking for this new application to be provisioned, and the chances were pretty good that they would get sucked into the maelstrom of server specifications, vendor contracts, and procurement times. Three months later, they might have something up and running. This was because each application needed its own resources, and those resources could only be provided by physical hardware. Given that providing accurate resource and performance specifications for any given application has always been difficult, and remains so, and combined with the capital expenditure-driven approach to datacenter expansion. Usually servers that were ordered and provisioned are massively over specked for their intended purpose. As it is actually easier to spend too much on a server once than it is to buy a more reasonably-priced server, and then go out and have to buy another one in six months’ time. Virtualization changed this, as we could fit more resources onto the physical kit. So the manager can now simply ask for a new virtual machine to run this application. Of course, they still don’t know the resource requirements, so they will probably end up consuming more resources than necessary. But still, there’s been some improvement in the process. In the past ten years, this paradigm has been under considerable pressure by service-driven architecture. The thinking goes something like this, the person requesting to run an application doesn’t care about the underlying infrastructure. They’re never going to be responsible for it, and they don’t want their own projects to be held back because of it, and they really don’t want to have to submit a request to a different department to have the necessary resources and access allocated. IT department doesn’t really want to get involved with the minutia of each application which runs on the systems for which they are responsible. IT department is not the application owners, but the IT department end up having to get so deeply involved in resource allocation and platform troubleshooting, that IT department end up becoming the defacto owner. The IT department would quite like the application owners to be able to provision what they want without having to go through them to make it happen. But, only if critical procedures, such as adherence to security practices, are complied with. Convenience cannot equate to noncompliance. Using service-driven architecture, the IT department can abstract the underlying datacenter infrastructure in such a way that fundamental resources like compute, networking, and storage are presented as a predefined and bundled service, which can be consumed by a customer like our application owner. After all, customers aren’t necessarily only external to our organization. The IT department can offer these services in such a way that all the underlying critical processes, such as security, are still adhered to. In fact, the service consumer cannot bypass these processes because they are baked into the service offering and, ideally, the consumer is not even aware of them. The application owner, or the service customer, has access to an identity-driven, self-service mechanism, like a web portal, which allows them to choose the services which they would like to run. Upon selecting, an automated business process is engaged, which provisions the application using the service mechanisms supplied by the IT department. The application owner gets the outcome they need without having to engage directly with the IT department, and the IT department keep providing services and supporting the underlying infrastructure without needing to be directly engaged with whatever is running on it. Many businesses have actually deployed such internal solutions, whereas for other global businesses, like cloud computing providers, this is exactly how their business model works.
Technological evolution now allows for massively centralize computing on a world-wide scale where consumers can request and pay for what they need rather than what they think they might need in 12 months’ time.
The nature of cloud computing is one which makes heavy use of virtualization and commodity hardware to provide an abstracted self-service user experience to customers or end users. The ultimate consumers of a cloud-computing service could represent different internal business units such as finance, HR, or application and development. Cloud computing is all about where you place the resources which serve your customers, and what the capabilities of the platform are.
Types of Cloud Computing
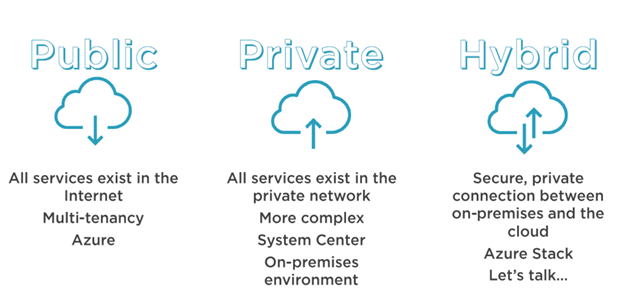
Figure 1
Cloud computing tends to come in three main types:
-
Private cloud computing: a private cloud is a cloud-computing environment which completely leverages on-premises infrastructure and services. As with a traditional mainframe, or client-server model, the business is responsible for the purchase configuration and maintenance of the hardware which supports the entire environment, including provisioning sufficient power and cooling and lifecycle management systems, such as protection, recovery, disaster recovery, and archival platforms. As such, no part of the overall solution needs to traverse the public internet in order to function, and therefore we can say that this environment is a private cloud. if the business is ultimately responsible for the purchase, configuration, management and maintenance of the physical computing infrastructure, then you’re certainly dealing with a private cloud.
- Private-cloud computing is generally favored by very large organizations which have a pre-existing significant investment in on-premises computing and dedicated datacenters, regardless of the provider.
- Some businesses also have extremely data sovereignty and security compliance requirements, which are imposed by industry or government regulation, or both, and having invested a significant amount over many years to achieve certification, the business is unwilling to go through the process again simply to move to a new external platform, regardless of the perceived benefits.
- Some businesses also tend to have very conservative corporate risk profiles and keeping all data and systems within its own direct sphere of control is a mandatory part of satisfying internal risk audits.
- The vast majority of datacenter implementations are still on-premises, although it has been rebranded and been provided with a makeover with automation and business-focused processes, private cloud still represents traditional on-premises computing, which has decades of maturity behind it. Don’t expect to see it vanish any time soon.
-
Public Cloud Computing: a public cloud provides services which a business can consume on as as-required basis, or a subscription-based model. These services can be consumed quickly, don’t require significant upfront investment, and don’t require the customer to bring any physical hardware. The business makes use of the services of a hosting provider, without the purchase, installation, and configuration of physical systems, the business doesn’t have a computing platform. Accessing public cloud services is almost invariably done via the public internet, although the traffic always securely encrypted. The principle behind public cloud computing is that you, as the customer, access the resource or the service that you need rather than having to build up and maintain a supporting infrastructure just so that you can get the outcome you’re looking for. It’s important to keep in mind that behind the scenes of all the scenario’s discussed, there is still a physical infrastructure running somewhere. There are still virtual machines and mail servers, and database servers, and disk arrays, and networking. But all of these supporting services are completely abstracted from the service consumer. The public cloud provider maintains these systems behind the scenes as a means to provide a wide variety of services, which can be consumed easily, but there is no escape from an ultimate dependency on physical systems running somewhere.
- Usually business turn to public cloud in order to meet specific needs, such as, supporting projects or work tasks which require agility and high levels of automation, providing sandbox environments to cater for isolated testing, providing compute resources or services to geographically dispersed offices or field workers, enabling existing enterprises to slowly move away from, and eventually decommission, on-premises datacenters, providing and end-to-end collaboration and management platform to born-in-the-cloud businesses.
- Business investment in public cloud might not be as wide spread as private cloud, but there is no doubt that public cloud practices are having a significant impact on the way in which senior level executives think about their own IT services and operations.
- Hybrid Cloud Computing: a hybrid cloud is a combination of private cloud and public cloud working together. What may come as a surprise is that for businesses which have invested in public cloud services, the hybrid cloud implementation is certainly the most common. The reason is that for most businesses, investments in public cloud does not, and in the vast majority of cases cannot, involve a wholesale migration to the cloud. Hybrid cloud isn’t simply a business which has services running in both an on-premises datacenter, as well as in one or more public cloud providers. By default, the services running in each environment are effectively isolated from each other and can be seen effectively as disparate datacenters which the business pays for, except that one of them is provided by a public cloud provider. To be considered a hybrid cloud, there needs to be some kind of interconnectivity between the on-premises and cloud-based environments, which enables a seamless transition from one to the other, and abstracts the service location away from the end user. So regardless of the business’s enthusiasm to ditch on-premises computing and head for the cloud, the common reality is that cloud migrations tend to start life as a hybrid cloud implementation, with the existing datacenter and the cloud providers environment coexisting side by side.
Understanding Public Cloud Services
Cloud computing is defined by a service-driven architecture where technology has evolved to a state whereby it can be offered out as a complete end-to-end service which can be quickly and easily consumed by end users and customers. Therefore, when discussing public cloud, we tend to define the major blocks of offerings as service offerings, appending as a service to the end of each, signifying that the provider has made a certain infrastructure-based solution available as an easily consumable service. Cloud Services are broken down into three main categories,
- Infrastructure as a Service, or IaaS. The public cloud provider offers raw computing resources in the form of one or more virtual machines. These are traditional datacenter resources, like CPU, RAM, disk-spaced storage, and networking.
- Platform as a Service, or PaaS. The public cloud provider offers direct access to an application-based service, such as a database server, or web application server. Rather than provision a new VM using IaaS and risk paying for CPU and memory which is never used, PaaS gives you access to the service you actually want.
-
Software as a Service, SaaS. The public cloud provider gives you access to a pre-built software application, which you can configure within the boundaries set by the application, but where you are totally abstracted from the underlying infrastructure and application services which underpin the service itself.
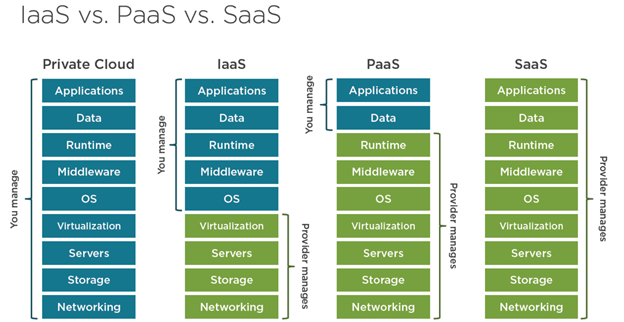
Figure 2
As you can see from the figure, the main difference between each of the different levels of service is principally the degree to which you as the customer are responsible for certain aspects of the overall solution, and the extent to which the service provider provides, and is responsible for, the services which underpin the end-to-end solution. The general rule of thumb is that as you delegate more responsibility to the cloud service provider, the range of solutions which can be run on these services becomes narrower, but the cost of provisioning a complete solution also reduces as you are paying purely for the service you require as opposed to wasting resources.
Architecting Infrastructure-as-a-service
When you are architecting an IaaS solution you need to consider:
- Compute: how to right-size the amount of CPU and memory resources your VM is going to need.
- Storage: how to choose the right types of storage and avoid being stuck with underperforming VMs, and network
The irony with IaaS cloud services, is that the easier it is to deploy something, the easier it is to deploy something which doesn’t suite your needs. Many businesses have ended up spending far too much money on public cloud services because they were able to quickly and easily spin up a number of VMs which were not correctly sized.
Choosing the Right Compute Services
The number and type of CPU cores allocated to your VM, as well as the amount of RAM, is probably one of the first most important choices you need to make when planning an IaaS deployment. This is because CPU and memory utilization are still the most expensive components of computing infrastructure, except for GPUS. When looking at VM sizes, a cloud provider will offer a range of preconfigured sizes, and these sizes will be your only options. Usually cloud providers break up their IaaS computing offerings into pre-defined sizes which are optimized for particular workloads, such as basic VMs with shared processing cores, or VMs with a very high core to memory ratio, VMs which have dedicated GPUS, or VMs which have massive amounts of memory for database and analytics workloads. Therefore, customers can choose first the appropriate workload, which is planned to run on the VM, and then choose a VM size from within a narrower range. So, how do you make sure that you select a VM size which is appropriate for the workload you’re looking to run in the cloud? If the workload you wish to run in an IaaS VM is already running in your on-premises datacenter, make sure that you can collect the performance metrics from the physical system, or VM, on which the application is currently running. You should try and get at least two weeks’ worth of performance data focusing on maximum and average CPU usage, and maximum and average memory usage. Average and maximum storage IOPS per disk is also very useful. This information will tell you about what you’re application actually needs. If it’s running on a VM with 6 cores and 32 GB of RAM, but the average CPU usage is about 15% and it never spikes above 35, then you can safely say that the application doesn’t need access to so many processing cores, so there’s no need to provision a cloud VM with the same specifications. And the same is true for RAM usage. Additionally, it’s always worth drilling down into the CPU usage patterns for each core to see whether the application is actually making use of multiple cores. If not, then either the application can’t use more than one core, so save yourself money and only provision one, or it’s been incorrectly configured, and you should rectify that as soon as you can as you will be paying for multiple cores and not using them. If the workload you’re planning to run in the cloud is one that you’re not currently running on-premises, start off by researching as much as you can about the advertise resource requirements, although keep in mind that many software vendors will overstate the amount of resources needed for their application to run smoothly simply to avoid situations where the application performs poorly due to a lack of resources. But what occurs if you choose a VM size, provision your new system, and install the application, only to discover that all the work you did in attempting to right-size the VM has still landed you with a VM which is either too small or too large? The solution is scaling. Most cloud providers give you the option to either scale up or scale down any VM. Public cloud IaaS allows you to increase or decrease the amount of allocated compute resources to any VM which has already been provisioned. Vertical elastic scaling almost always requires that the VM is restarted. This makes sense as from the operating systems point of view, you are effectively removing or adding physical hardware. Once you’re successfully up and running on an IaaS VM, gathering performance metrics remains of critical importance, as this is the data from which you can make informed choices. If it seems that the application workload on your new VM isn’t performing as you think it should, don’t jump straight into triggering a scale up until you’ve reviewed the performance logs. Poor system performance can be caused by issues elsewhere.
Choosing the Right Storage Services
For virtual machines, most cloud providers offer two types of storage on which to store virtual disks Hard disk drive (HDD-based storage), or Solid-State disk (SSD-based storage). SSD storage is terrific for workloads which have high IOPS requirements, whereas hard-drive-based storage is more appropriate for workloads which need lots of space, but lower IOPS. Beyond storage for virtual machines, public cloud providers offer storage for all sorts of uses, such as simple storage for files, repositories for container images, content delivery for websites, a source for gathering event logs from disparate systems, or even as a repository for long-term archival storage. Choosing the right kind of storage for each workload is important, as different services are geared toward specific business scenarios.
Choosing Networking Services
When architecting an IaaS-based solution, you need to take networking into account just in the same way as you do when designing something in you on-premises environment. As a virtual machine is still a virtual machine, and to communicate with anything other than itself, a VM needs to be attached to a network, which means that it still needs at least one network interface and some form of IP address allocation. When you create a new virtual network, it can be tempting to go with whatever the cloud provider suggests by default, but remember that the provider doesn’t know what you know, so the defaults may not suite your short-term or long-term needs. Most IaaS-based networks are still based on IPv4 address ranges. This means that you still need to plan out IP address ranges and subnets, and the choices you make depend upon your future plans for this new virtual network. If there is even the smallest chance that you might want to connect this virtual network to your on-premises network, then you should absolutely ensure that the address base of the virtual network does not overlap your on-premises network. You have an on-premises network which uses an IPv4 If you access your new VMs using their assigned public IP addresses, then the routing from the public IP address to the internal IPv4 address is handled by the provider, and you never need to worry about the internal IP addressing structure. In fact, you could have multiple virtual networks, all with exactly the same IP address range, as long as those virtual networks always remain isolated from each other. Later, you need to provision a hybrid cloud environment, which involves connecting your on-premises network to the cloud-based virtual network using a VPN. Now you have a problem because it is quite difficult to route network traffic between two hosts which reside on independent networks, but with overlapping IP ranges. So if there is even the slightest chance that you’ll want to connect a virtual network to another network in future, whether on-premises or another virtual network in the same provider, or even in a different provider, then endeavor to keep your IP address ranges unique.
Architecting for Infrastructure as a Service Resilience
Resilience, is ensuring that your Infrastructure-as-a-Service-based workload stays up no matter what’s occurring under the hood. Geo-redundancy, making sure that even a datacenter outage isn’t going to ruin your day, and self-healing, how your workloads can fix themselves. There is a very common misconception around the public cloud services. Especially Infrastructure as a Service, which is that once you deploy a resource like a virtual machine into a public cloud environment, you don’t need to worry about it anymore in terms of ensuring that the VM stays online and that the data is protected. The service provider will handle all the physical infrastructure up to and including the virtualization layer, but everything above that is the responsibility of the customer. The implications of this are that if there are any operating system patches to be applied, it’s the customer’s responsibility to apply them. If there is a problem with any application installed on the system, it’s the customer’s responsibility to remediate them, and if there’s any important data on any of the disks attached to the VM, it’s the customer’s responsibility to ensure that it is protected appropriately. The provider makes sure that the underlying infrastructure, which supports your VM, is robust and stable, and if there are any issues, like disk failures, that these will not adversely impact your VM. Combined with active maintenance and monitoring allows the provider to offer a service-level agreement for the resource which you have provisioned. Let’s say a 99% uptime guarantee. Though 99% uptime SLA means that you could reasonably expect your VM to offline for a total of 3.65 days through the year, although not all at once. Faults occur and equipment fails, and cloud providers are not immune from this. Because they operate at such large scales, providers have to factor in a certain background rate of equipment and peripheral failure into their business models. The underlying infrastructure is designed to minimize the impact of any hardware faults, but outages cannot be prevented completely. Also, the cloud provider still has to maintain the operating systems which provide the virtualization layer. In the same way that patches and updates need to be applied to the operating system of your IaaS VM, so to for the supporting hosts. If a patch can be applied without needing to reboot the system, then terrific, but otherwise a reboot will be necessary and the VMs running on top will also need to be restarted for a short amount of time. You should therefore anticipate a certain amount of downtime for your IaaS VM. So with this in mind, what can you do about it?
Architecting for High Availability
Fortunately, the principle behind this solution is very much the same as if you were architecting the workload to run on-premises. We need to build resilience in multiple levels in order to ensure this, but these tasks are the means, not the end. Too often, those responsible for the technical aspects of a solution focus, on the technical components, and lose sight of the reason that this technology exists in the first place, and why we need to care about it at all. For a database solution for example, we ensure that we are using a database server platform that supports high availability across multiple VMs. This can take several forms such as active/passive replication with failover, active/active synchronous replication with failover, or active/active asynchronous replication, again, with failover. The full solution which enables these HA scenarios will differ from product to product, and this is where an in-depth knowledge of the database solution is necessary. In the event of an outage on the nominated primary, assuming that there is such a solution role, there needs to be a system in place which informs the other database servers of the event, and allows another system to assume the role of the active primary, accepting incoming connections. By building multiple VMs, we can configure the VMs from the perspective of the cloud provider as a single service. The provider can then distribute the VMs so that they are separated from each other within the datacenter, so that if there is an outage due to a hardware fault or a host reboot, only one VM within the configured service should be impacted and the others keep on running. This robustness ensures that the database is still available, but this doesn’t necessarily help the end users if they are still querying the offline database server. Therefore, the method by which they need to communicate with their solution, usually a fully qualified and network domain name, also needs to be aware of the failover events. This is usually achieved by means of a network load balancer. Using health probes, the load balancer can tell when one of the database servers, which it is actively monitoring, has gone offline, and redirects all incoming traffic to a specified alternative. In this way, from the customers point of view, although there has been an outage behind the scenes, the core service is still available for consumption. This architectural model is the one which must be adhered to when building solutions using Infrastructure as a Service. Given that we know that any single VM running in a public cloud environment must incur some downtime, no matter how brief, to deploy a workload in a single VM is the same as accepting outages. Architect your solutions assuming outage, and you can actively mitigate against it and give your customers the best possible experience.
Geo-redundancy
So far, we considered making services more resilient within the boundaries of a single public cloud datacenter. What about when that entire datacenter goes down? It doesn’t matter how robust your solutions are if you can’t access them. We can take advantage of the fact that to provide a robust service, public cloud providers don’t just have one datacenter, but rather multiple datacenters spread out around the world. Part of the reason for this is pragmatism. Customers in one geo-region would prefer to access a datacenter which is physical nearer to them for lower latency, but another benefit is that you can use the geographically dispersed nature of cloud datacenters to your own advantage. Because the services on offer in one datacenter are generally the same as in the others, it is possible to replicate the sane solution pattern across multiple datacenters. Using an external load balancing and routing service by the provider, we can direct customer traffic to the nearest datacenter to take advantage of low latency, but if a datacenter is offline, the external load balancer can automatically redirect traffic to another datacenter which is still online.
Elasticity and Self-healing
One of the things which is unique to public cloud environments, which we can take advantage of, is using horizontal elasticity to enable self-healing services. Horizontal elasticity describes scale-in and scale-out scenarios. We have architected for robustness within a single datacenter, and we have catered for the potential outage of an entire region, but we haven’t catered for spikes in demand. Let’s say that there is a surge in demand from users in Ontario. This may lead to the IaaS instances in the Toronto datacenter becoming saturated and the servers becoming unavailable. With geo-redundancy, the external load balancing service will flag that datacenter as offline and will redirect traffic to another one, where the process simple repeats. It’s not a great outcome for the business or for customers. Using horizontal elasticity, we can allocate additional IaaS instances to the solution automatically to support the additional load, and then reduce the number of instances when demand drops. We only pay for the additional instances for the time that they are in existence.
Architecting Platform-as-a-service
The architectural considerations when building out a solution using Platform as a Service aren’t so very different from IaaS. There are some differences of course, but overall what is good practice for one, is good practice for the other. What’s important to look at is why you might want to use PaaS over IaaS, and what the benefits are. PaaS reduces the amount of responsibility which we as a customer have. Just in the same way as we endeavor to architect IaaS solutions to allow the customer just to focus on the service which they care about, PaaS offers us, as cloud architects, the same opportunity. If we want to provision a database service for our users and customers, why go to the trouble and expense of architecting and deploying and IaaS-based solution if we don’t have to? If PaaS solution delivers the same outcome and meets our business requirements, then we should need a compelling reason not to choose that option. It is generally that for any given PaaS-based solution on offer, architecting and deploying the same service using IaaS is more complex and invariably more expensive. PaaS solutions are focused on delivering a very specific outcome rather than a broad platform on which you can deploy whatever you’d like, cloud providers are able to make much more efficient use of the underlying resources which support PaaS offerings as opposed to IaaS. It is this less expensive, more efficient use of resources which is the true potential of cloud computing, and lies at the heart of digital transformation. Digital transformation is the process by which a business takes its existing VM-centric approach to solution delivery and moves it to a service-based approach, transforming existing applications and workloads to work within a PaaS framework, and thereby simplifying architecture, increasing delivery speeds, and reducing operating costs.
Architecting PaaS Web Solutions
PaaS-based web services enable you to provision a dedicated web hosting environment running on a particular operating system, Windows or Linux, with a certain amount of computing resources allocated. Yes, we still should design an appropriate amount of CPU and memory resources, but this is the nature of application architecture. Applications needs resources to run, and the cloud providers relies on us to let it know how much to allocate. However, despite using the operating system and resource capacity, we don’t need to worry about configuring any of it. All of that is done by the provider. Once provisioned, the cloud provider will run our hosted web servers in a preconfigured environment with a number of configurable runtime options, such as the desired version of the .NET framework, if running on Windows, whether or not PHP should be enabled, and if so, which version, whether the architecture should be 32-bit or 64-bit, what the virtual document should be, and any virtual folders. Selecting any of these options does not require us to have direct access to the underlying operating system, which has been abstracted away from us. We make our choices based purely on what the application needs in order to run. Architecting for redundancy within the datacenter is no longer a consideration, as this is built into the service fabric and geo-redundancy is achieved the same way as with an IaaS-based solution. Once the service is running in one datacenter, deployed to a second or third datacenter using the same deployment code and scripts and using external load balancing service to provide a unified frontend to end users and customers. For applications which are born in the cloud, select a PaaS service from a cloud provider, which offers the hosting configuration which your application requires, and deploy. For applications that started life on the premises and have been hosted on VMs with custom, and often very specific configurations, is where digital transformation starts to get harder. As PaaS-based web hosted environment represents a more restricted configuration than the equivalent environment running on IaaS. A PaaS solution is more restricted by necessity because the cloud provider needs to be able to standardize the configuration to run an efficient service. However, if your application can only run if a text file with a specific name exists in a particular location, or it requires an obscure dependency which has to be manually installed and configured, then these requirements are going to act as blockers to a PaaS transformation where the needs of the application must be balanced against the restriction of a standardized environment. At this point, you need to perform a cost benefit analysis, which measures the cost to the business of transforming the application to a cloud-ready state, against the benefit to the business of such a transformation. Clearly, even though the application might run more efficiently in a PaaS environment, the costs of transformation outweigh the benefits to the company, and it is a more sensible decision to maintain the application in its current state until it can be retired.
PaaS Database Solutions
The reason that database services are the most common form of PaaS offerings is because of web application services. PaaS-based web applications usually need to talk to a back-end repository of data, and this tends to be a database of one flavor or another. The process of architecting a database service is, much simpler than designing the same solution on IaaS. Cloud service providers offer a range of database services, which are designed to support specific database types, such as Microsoft SQL, MySQL, or PostgreSQL. The database service is allocated a certain amount of physical resources depending on your requirements. There is a different in approach to architecting PaaS database solutions depending on whether the database is being built for the first time in the cloud, or whether it already exists on-premises or in IaaS, in which case it is running on a dedicated database server instance with a specific configuration.
Code-driven Infrastructure Development
As you migrate services to PaaS, or start building new PaaS-based solutions, one of the things which becomes clear is that the amount of configuration required over the equivalent solution built in PaaS, is dramatically reduced. Another thing which will become very apparent is that all cloud providers promote deployment, management, and configuration of their PaaS offerings using automation. Each provider has its own implementation and preferred methods, but all are very consistent in enabling programmatic interaction with its services. The implications of this when working primarily with PaaS is that you are more likely to already working with automated deployment mechanisms, especially with web applications. Developers work on application code, commit that code to a source control management system, and an automated continuous integration continuous deployment, CICD, system picks up those new code changes, runs them through a battery of automated tests and checks, and then finally deploys the code into production. The underlying PaaS services which underpin our web and database applications, can be defined as code, we can define all our solutions as code. This has many advantages. It establishes a source of truth as to what our PaaS infrastructure should look like at any point in time, it eliminates the need for any kind of manual deployment or configuration, it promotes and enforces correct patterns of behavior in terms of change management, and it lowers the barriers to awareness between the application development and infrastructure operations teams, or DevOps. There are many popular open-source automation and deployment platforms out there, like Ansible, Jenkins, Terraform, and Spinnaker. PaaS makes it much easier to treat our infrastructure solutions as code, which in turn encourages us to adopt a developer mindset and gain experience with developer tools. In this sense, PaaS has been one of the biggest disrupters to the traditional definition of an IT professional. IaaS allows us to continue doing what we already do, whereas PaaS encourages us to think completely differently
Security Considerations
Identity Management
The consequences can be bad enough when the account in question is tied to your social medial accounts. But when the account is an administrator of your public cloud environment within which your production workloads are running, well, the consequences have business, financial, and possibly even criminal implications. If the administrative account which was used to provision your public cloud environment is compromised. By default, this administrator account has access to absolutely everything within that environment. So, someone who controls this account can access any resource or service deployed within the environment, and can block access to other accounts, preventing attempts to rectify the situation. VMs can be accessed, and data can be siphoned off. So, it might be a good idea to protect those accounts, don’t you think? However, here are a few tips for protecting any account with significant levels of access to anything really. The first one is to choose a good password. The use of a centralized password manager is quite common, but then you must protect access to the password manager too. Secondly, multifactor authentication cannot be overestimated. Depending upon the capabilities of the identity provider, you should also look at implementing conditional access rules and fraud detection. Conditional access rules allow the identity provider to determine whether to challenge the authentication attempt against the accounts with stricter controls. By comparison, fraud detection looks for patterns of behavior which are suspicious in nature, like an authentication attempt coming from the U.S. and then another one coming from Europe 5 minutes later. These layers of protection don’t offer a cast-iron guarantee that your admin account will never be breached. No system can guarantee 100% protection, but by applying multiple layers of defense, the likelihood of a breach becomes significantly less. Then consider how to limit the damage which these accounts can do in the event of a breach, because it is always important to assume that there will be a breach at some point, and plans need to be in place to reduce the impact. When you provision a cloud environment, there is usually a one-to-one mapping between each environment and the admin account which was used to create it. As most partners require an initial account to create and access each environment, if you place all your workloads into one environment, then if you assume that the admin account used to create the environment has, or potentially could be breached, then all of your cloud services are at risk. Another approach is to distribute your workloads and services across multiple environments, if you use different accounts for each environment, then if one account is breached, the damaged, or the blast radius, is significantly reduced. While this approach is a bit more cumbersome and require management of multiple public cloud environments, it does not impede the functionality of any workloads or services you may wish to deploy, and it offers a reasonably balance between security and convenience.
In addition to planning for account protection and breach mitigation, it’s important to architect how the identities in your cloud environments will be managed. Most cloud providers don’t assume that you have your own pre-existing identity platform, such as an on-premises identity system, which they should plug into. They all offer an identity service, which, at the very minimum, meets the needs for managing any environments which you have provisioned with them. If you have your own on-premises or IaaS-based identity platform, which you use to create and manage users, groups, permissions, and passwords throughout their lifecycle, then making use of a second separate identity platform becomes something of a management problem. This is where identity federation comes into our architectural plans. Most cloud providers will support a form of identity federation, such as Security Assertion Markup Language, SAML, or OpenID Connect, which enables the cloud provider to query a nominated identity source for account verification and authentication. Depending on the platform, the identity federation can also handle account creation requests on the cloud provider side.
Role-based Access Control
Role-based access control (RBAC) is a mechanism which allows you to adhere to the principles of Just Enough Administration. Each account should be assigned the permissions which gives them sufficient rights to do the tasks for which they are responsible, and no more. When considering role access, spend some time learning what kind of role-based controls your cloud provider offers, because each has a different approach to security and permissions, but whatever mechanism they use, make sure you architect permissions to roles and implement RBAC.
Configuration Management
Public cloud providers are set up to streamline the consumption resources, and in order to do that, they make a number of assumptions about the configuration of any services which you may request. This includes configuration choices around security, diagnostics, and configuration management. Our responsibility, as cloud architects, is to know what the options are, and how best to implement them. Configuration management is where you deploy resources and services according to a predetermined architectural pattern, which you have already verified and approved. Configuration management then enables you to update the architectural patterns centrally and have the updates rolled out across your cloud environments so that you can be confident that all your resources and services are configured according to the most up-to-date architectural decisions. Let’s say that you have deployed a number of virtual networks throughout your public cloud environments using the service template technology. The templates contain all of the information about how a virtual network is to be configured. The templates are parameterized so you can simply pass in some dynamic arrays for the different networks you wish to deploy, and the cloud provider’s deployment APIs merge the data and handle the deployment. You use templates to deploy a 1.0 version of your approved network configuration, making sure that the templates, and any associated scripts, are all stored in version control, then at a later stage, there is a requirement to add another subnet to all existing virtual networks. Because you have invested in a programmatic deployment, you can update the templates to include the configuration details for the new subnet, update the deployment array properties accordingly, and increment the configuration version to 1.1, perform another deployment, and the existing services are not deleted and recreated, which would be pretty bad for a virtual network which is already in use, but are rather simply updated to reflect the new configuration. Finally, using basic programmatic queries, you can easily determine which version of the template configuration your resources are using.
Operating system and application-level configuration management is just as important as resource configuration because it’s very easy for the configuration of an operating system, or application, to drift over time away from its original specification. This may not sound like a major problem, but given that the software configuration of any VM also incorporates things like the firewall, local user accounts, and security settings. It quickly becomes clear that configuration drift is something best to avoid. As the configuration of the operating system and applications is our responsibility, we need to ensure that we have a configuration management system in place.
Security Compliance
How do you know whether or not the configurations which you have templated are actually being adhered to, or for that matter, how do you know whether your resources are actually secure? Depending upon the services offered by your cloud provider, you may be able to make use of a SaaS offering, which can document and track the resource configuration of your environment, allowing you to see visually how the environment is changing over time, and also flag any potential issues. Some cloud providers also offer configuration management recommendations, which will enable you pick up any obvious security gaps which can be quickly filled, such as VMs exposed to the internet via a common management port, or the lack of an active resource-level firewall. We implement a dedicated configuration management platform to control our environment, but then use a different platform to verify that the results are as expected. There are many tools on the market which can provide you with independent audits of your cloud environment. Automated compliance is, in many ways, the other half of the configuration management problem. You really need both solutions working well in order to have confidence in the configuration and security integrity of your cloud environment. When dealing with public cloud services, we tend to assume, correctly, that all data is encrypted in transit. After all, whenever we interact with a provider’s services, we are always using HTTPS so the traffic is secure, and the same is true of internal traffic within the providers datacenters. But what about data at rest? Interestingly, most of the resources and services which we have looked at throughout the course, like VMs and VM disks, storage accounts and database services, all have the capability to be encrypted such that the data is encrypted at rest, but these options are not automatically enabled. Cloud providers are able to offer encryption as a SaaS offering, making use of infrastructure internal to their own environments, like public key infrastructure, PKI, certificate authorities, and hardware security modules, HSMs, to securely store secrets and encryption certificates. However, these are separate services in their own right, and cloud providers don’t automatically force you to subscribe to another service, just so that you can use the service which you were originally interested in. But now that you know data encryption at rest is available, leveraging the providers own services, it’s absolutely something which you should consider, given the addition cost and configuration, it may not be worthwhile encrypting absolutely everything in your cloud environment.
Diagnostics
As with encryption, diagnostic and event logging is supported by all cloud providers on just about every resource and service you can possibly deploy, but it is rarely enabled by default. Enabling diagnostic logging on all of your services can generate a lot of stored data over time, which you will be paying for. However, you should definitely start enabling diagnostic logging on pretty much every service which supports it. This will give you insight into what’s happening across every resource and service which you’re paying for. Logs not only provide rich data into the usage patterns and performance of your services, but they also enable you to audit security events, like authentication attempts, and internally event logs from the operating systems of IaaS VMs. This is invaluable data which can keep you on top of what’s going on. The trick is how best to ingest and make sense of all that data. You’re certainly not going to read through each and every log entry. But you need a way of making sense of all of that data. There are plenty of products which provide a detailed log analysis such as Splunk.
At a high level, cloud service providers offer the ability for you to create your own event-driven processes powered by the providers infrastructure. As we deal with public cloud environments, which are continually increasing in scale and complexity, the requirement to be able to interact with these systems in ever simpler and more efficient ways will be increasingly more important.
