
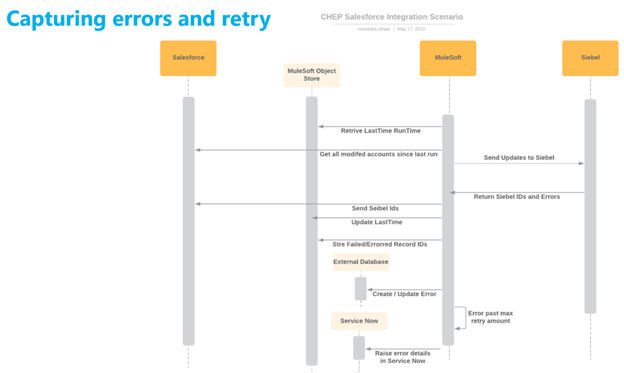
In addition to MuleSoft connection Retry, this pattern adds the retry of rejected or failed records by the target system validation, in case another retry would succeed
Scenario
In a recent project I was working on, I needed to keep Salesforce objects updates synchronized with Siebel. The basic integration scenario is shown in Figure 1.
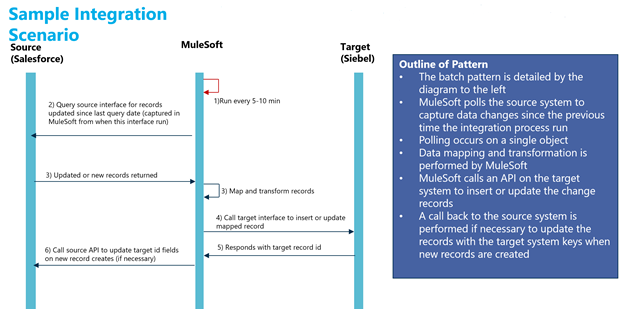
Figure 1: Integration Scenario
There is one complication though, sometimes Siebel will reject updates or new records as validations fails due to missing data or racing conditions with other data records. Rather than letting records fail and logging errors for support or the user to resubmit, a retry approach after a period of time could remedy most of the errors. As depicted in figure 2, the logic for the synch is as follows:
- The synchronization job is schedule to run every 10 minutes.
- Fetch the last datetime the synch had run (in case the synch job was stopped for any reason such as maintenance).
- Fetch all modified or created accounts IDs from Salesforce since the last run
-
Process Accounts
- Fetch the Account Objects for the records ID from steps 3
- Do the necessary conversions to Siebel format and send the updates to Siebel
- Send the Siebel IDs for accepted records to Salesforce
- For records that got rejected by Siebel, keep track of the record IDs and store them in MuleSoft Object Store with the number of retries.
-
If there are Stored Rejected Record IDs from a previous run in MuleSoft Object Sore
- Fetch the record ID from Object Store
- Execute Process Accounts step 4
-
If the number of retries exceeds 3 times log the rejection and create a ServiceNow ticker so support can track and resolve the issue
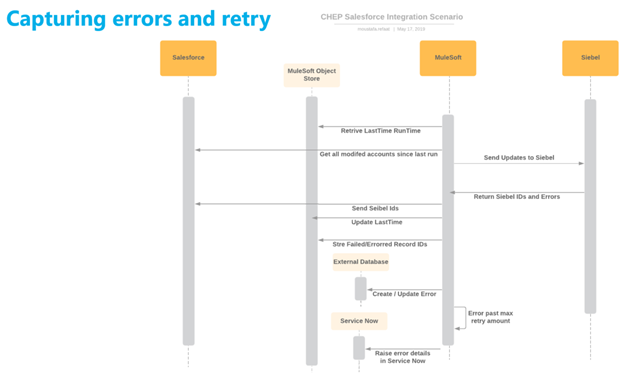
Figure 2: Synchronization with Capturing errors and Retry
The Sample
In the sample code found at my GitHub (https://github.com/RefaatM/MuleSoft_SyncWithRetry), I am simulating Siebel with a MySQL DB. The implementation will synchronize the Salesforce Account changes with a table in MySQL DB. The next few sections, walks through the code details
Project Structure
When you open the sample code in AnyPoint Studio, you will find the project code consisting of:
- Src\main\mule which contains the 4 workflows
- Src\main\java which contains 1 java helper class
- Src\main\resources which contains the configurations config.yaml
The other packages are the standard packages of any MuleSoft project. The 4 Workflows, 1 Java class and config.yaml implement the solutions.
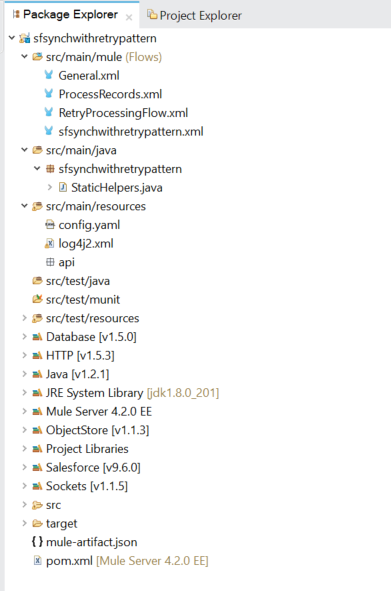
Figure 3: Project Structure
General Workflow and Global Configuration

Figure 4: General Workflow
Following the MuleSoft best practices the Global workflow is where you will find the Global Exception Handler in this sample it just logs the error (figure 4) and the global configuration to use a config file for the different environments and the connections to Salesforce and MySQL DB (figure 5).

Figure 5: Global Configuration
Figure 6 shows that the Default Error Hander is set to the “General Error Handler” in the General Workflow. For a refresher on MuleSoft Exception Handling see MuleSoft: Understanding Exception Handling/
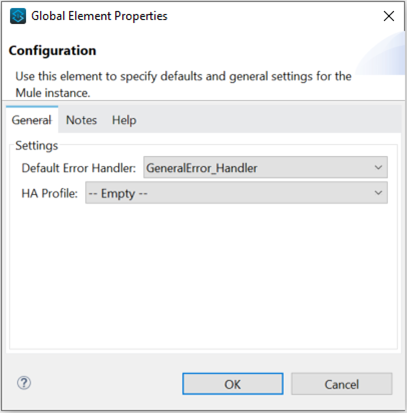
Figure 6: Global Error handler Configuration
Figure 7 Shows the setting of config.yaml as the source for the configuration information. It is important not to hard code any environment or properties.
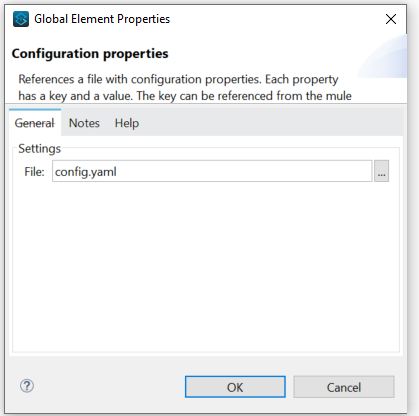
Figure 7: Configuration properties source file
The listing below shows the contents of the config.yaml . All sensitive information is masked with * to run the sample you will have to enter the proper information for your environment.
sfdc:
username: “**************”
password: “***********”
token: “*****”
db:
host: “localhost”
port: “3306”
user: “root”
password: “****”
database: “synchsample”
Figure 8 shows the configuration of the Salesforce connection with parametrized information to be retrieved from config.yaml
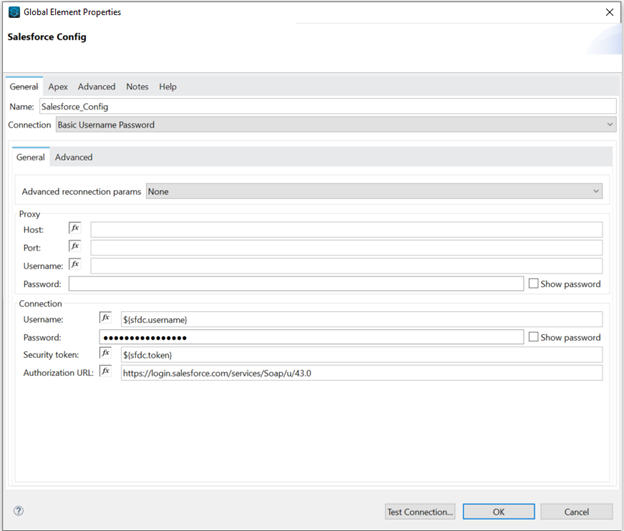
Figure 8: Salesforce configuration
Figure 9 shows the configuration of the MySQL DB connection with parametrized information to be retrieved from config.yaml
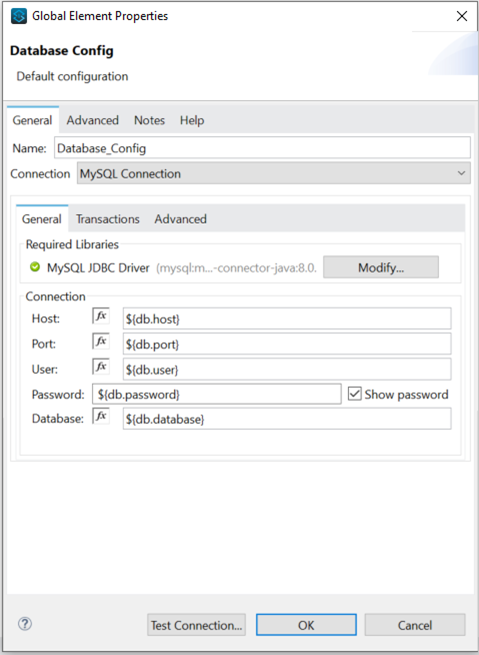
Figure 9: MySQL Connection configuration
MainFlow

Figure 10: MainFlow
The mainflow is triggered by the scheduler the logic is :
- Log the start time
- Call the Get Duration subflow
- Query Sales force for update accounts
- Convert the result to a list of IDs to query
- Call Record Processing subflow
- Log the operation is finished
- In case of any error just log it.
CallRecordsProcessing Workflow
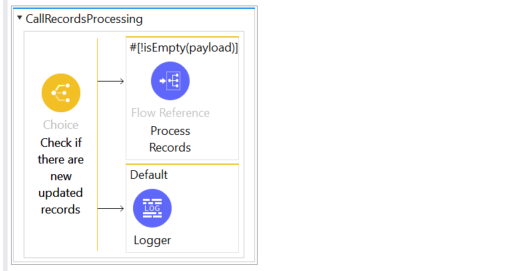
Figure 11: CallRecordProcessing Subworkflow
-
Check if the list of record IDs is empty
- Not Empty: call Process Records
- Empty: log no modified records found
GetDuration Subworkflow
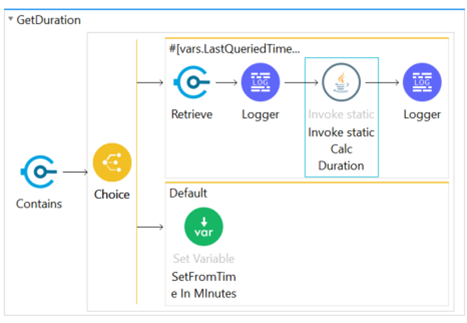
Figure 12: GetDuration Subworkflow
- Check if Object store contains saved lastTimeRun
-
Contains LastTimeRun:
- Fetch the lastTime
- Call Helper Java method to get the duration
-
Does not contain LastTimeRun:
- Set the duration to 10 minutes
The Java method code is listed below which just calculates the duration since last time the workflow ran till now in minutes
package sfsynchwithretrypattern;
import java.time.Duration;
import java.time.LocalDateTime;
import java.time.ZonedDateTime;
public class StaticHelpers {
public static long getDuration(ZonedDateTime lastTime) {
LocalDateTime now = LocalDateTime.now();
Duration duration = Duration.between(now, lastTime.toLocalDateTime());
return Math.abs(duration.toMinutes());
}
}
StoreRetryAccounts Workflow

Figure 13: StoreRetryAccounts SubWorkflow
-
Check if there are stored RetryIDs
- RetryIDS stored: Append the new IDs to the existing IDS
- Does not Exist: set the store load to the new IDs
- Store the updated value
ProcessRecords SubWorkflow
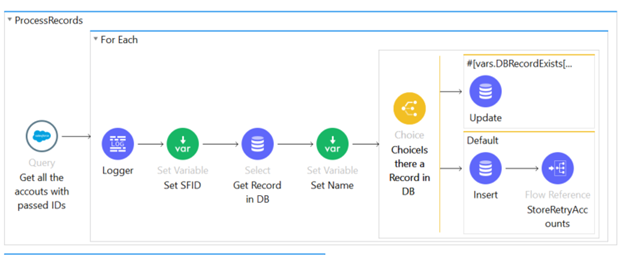
Figure 14: ProcessRecords SubWorkflow
- Retrieve accounts with IDs
-
For each retrieve account IF
-
Check if the Account info exists in the DB
- Exists: update the account information
- Does not Exist: Insert a new record
Note here I am taking an new records and saving them in the retry ID to simulate rejections. This should be moved to where you receive results and the errors
-
RetryProcessing Workflow

The retryprocessing workflow is triggered by a schedular, it starts with:
-
Check if there are any retry id stored
- Exists: retrive the stored IDs and process them
- Does not Exist: Log no Stored IDs were found.
Conclusion
This is a good way to handle transient errors that occasionally occur during integrating system, when a simple retry might resolve the issue rather than having to ask the user to re-submit or getting support to chase the error. I hope this helps you in your projects. Feedback is welcome.

Figure 15: MySQL DB Table with Updates
